There’s a theorem that, although its formulation is trivial, is of paramount importance in many things, including data compression. I’m talking about the frivolous theorem of arithmetic, of course. The theorem takes many forms, but one being:
Almost all natural numbers are very, very, very large.

The converse implies that there are a lot more big numbers than there are smaller numbers. Of course, this is trivially self-evident. But this trivial theorem can serve as a brutal reality check for many hypotheses. For example, one can use the frivolous theorem of arithmetic to disprove the existence of a lossless data compression method that compresses all inputs to smaller bit strings.
First, let’s dissipate the ambiguity around large and small. In the usual meaning, a number 

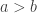
The proof itself is that, as the theorem states, there are a lot more large, and therefore long, numbers than small, therefore short, numbers, so, not all long numbers can be mapped (using a bijection, as required by losslessness) to a shorter number 2. This means that if one looks at files (or data) as strings of bits which in turn can be considered as the binary representation of numbers, the lossless data compression algorithm can be seen as a function 
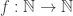
In fact, only the only bijections that can exist will map natural numbers in a way that some may be mapped to shorter numbers, but almost all will receive a longer or equal size number.
If your lossless data compression is well thought for your source, it will map the bit strings (numbers) that corresponds to likely inputs to shorter numbers. It may work because normally real-life data (before it’s compressed) does not occupy the whole possible input space. Consider, for example, the set of all possible C++ source code files. There’s a infinite but countable number of such files, but the set of C++ files is not very dense on the set of all possible files of any kind. If fact, it will be an extremely tenuous subset of all possible files; it may therefore be possible to devise an algorithm
On the other hand, if your expected input is just any file, it is unlikely that your algorithm will be able to compress even most of them. Most of them will, due to the frivolous theorem, actually expand as most of the input bit strings—or file, or data, same thing—will be mapped to longer numbers.
The result of your algorithm necessarily falls into one of the three following categories:
- Compression is achieved in general. This is because most of the inputs you have correspond to the expected subset of inputs that gets mapped bijectively to shorter numbers. Unexpected inputs are expanded, but are rarely seen; thus you achieve compression on average.
- No compression nor expansion. This is because your method is the identity, or a function that maps numbers of a given length (in bits) to numbers of the same length, most of the times, compressing some, expanding some. The simplest of those mappings is the identity,
but that’s not the only one (as is pointed out in the comments). It may be that the algorithm maps (bijectively) integers to integers of the same length on average. In either cases, numbers can be displaced but the average compression is asymptotically null.
- Expansion is obtained in general. This is the case where you try to compress just about anything. Normal files found on computers have a lot of internal structure and are therefore not ‘random’ in the Kolmogorov sense, so they may result in some compression; however, already compressed or random files will expand. In general, therefore, expansion is obtained rather than compression.
*
* *
We have somewhat supposed that if files are considered as (rather large) natural numbers, the length of the bit string is somehow known beforehand. In a real file system, the length of the file is not stored in the file itself (although it can have some information about its own length, but in general it’s not the case) but in the file system. This means that there’s a certain quantity of information that is removed from the file (its length) to be placed somewhere else, that is, in the file system meta-data. In many cases, we can wave that (small) quantity of information away in our calculations because it is essentially negligible when the files are large, but for smaller inputs, it is significant. I’ll be back on this topic later on, because it is very interesting. For now, let’s say that if 
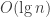
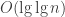
1 The original text stated only smaller numbers, rather than shorter numbers, leading to ambiguous—and therefore inaccurate—statements, as pointed out in the first comments. Many thanks to Arseny Kapoulkine.
2 See the first comments to understand why we must specify shorter rather than merely smaller.
3 The algorithm would consist in computing the order of enumeration of valid C++ files. Probably 0 would map to the shortest correct C++ file, the empty file. 1 would map to something like “int _;”, and so on, until you eventually reach, by enumeration of all possible files, the interesting files.

I believe that the reasoning about compression is inaccurate (of course I don’t dispute the result). There are a lot of bijections that make most input numbers smaller. I.e. given a constant M, f(k) = (k % M == 0) ? k + M – 1 : k – 1. For M=2, even and odd numbers are swapped, giving 50% reduced numbers and 50% expanded; for larger M you can get as many reduced numbers as you can. Of course, the average compression is still zero.
That’s actually a good observation. It’s like you rotate a block of numbers, sending the smallest to the top and shifting down the
numbers, sending the smallest to the top and shifting down the  others (we would devise a scheme where we rotate a block of
others (we would devise a scheme where we rotate a block of  numbers
numbers  times, deciding how many we demote or promote).
times, deciding how many we demote or promote). 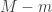 numbers map to smaller numbers, and we choose
numbers map to smaller numbers, and we choose  as large as we can.
as large as we can.
But what about their length, in bits? Some will reduce, if your block of is across a boundary around
is across a boundary around  for some
for some  , but all the others will increase length. If you’re somewhere far between
, but all the others will increase length. If you’re somewhere far between  and
and 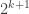 you get no change in length; all numbers are
you get no change in length; all numbers are  bits long.
bits long.
On the long run, you get only a tiny bit of compression for some, and expansion for most; that’s been demonstrated before. In addition, you have the extra information about to store somewhere in the codec.
to store somewhere in the codec.
Thanks for pointing that out. I’ll revise the text to reflect that
[…] Theorem of Arithmetic By Nicolas A. Bérard-Nault Steven Pigeon recently introduced the Frivolous Theorem of Arithmetic in his Harder, Better, Faster blog. As a complement, I shall present a rigorous, rather useless but […]
Yes, this is a rotation. In terms of bits most will stay the same, not expand, some will lose 1 bit, some will gain a lot of bits.
That’s assuming that logM bits are stored elsewhere in a global dictionary, or that the M is fixed forever.
[…] that is trivially true, pretty much independently of what we call “small” (see here)). In this case, universal codes are ideal. They’re in general relatively simple, and we can […]
Corollary. Almost all numbers are larger than the Frivolous Theorem of Arithmetic suggests.
Oh, that’s good!