There’s always a number of graphics primitives you will be using in all kinds of projects. If you’re lucky, you’re working on a “real” platform that comes with a large number of graphics libraries that offer abstractions to the graphics primitives of the OS and, ultimately, to its hardware. However, it’s always good to know what’s involved in a particular graphics primitives and how to recode it yourself should you be in need to do so, either because you do not have a library to help you, or because it would contaminate your project badly to include a library only to draw, say, a line, within an image buffer.

Lines are something we do a lot. Perfectly horizontal or vertical lines have very simple algorithms. Arbitrary lines are a bit more complicated, that is, to get just right. This week, let us take a look at a few algorithms to draw lines. First, we’ll discuss a naïve algorithm using floating point. We’ll also have a look at Bresenham’s algorithm that uses only integer arithmetic. Finally, we’ll show that we can do better than Bresenham if we used fixed point arithmetic.
Assuming that 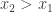
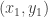
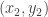
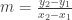
Using this, the 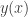
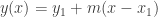
Which expands to

Implementing this with a somewhat naïve approach, that is, using a slope 
m=(y2-y1)/(float)(x2-x1);
float y=y1;
int x;
for (x=x1;x<=x2;x++,y+=m)
putpixel(x,y,color); // implicit rounding
// of y to int
In this piece of code, we suppose that 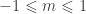
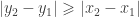


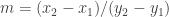
A priori, you may think that on modern processors, that’s not much of a problem and you could be right. However, converting a float to an int is a costly operation. On my 32 bits box (which doesn’t have SSE), using gcc -fno-inline-functions -O3 -S -masm=intel lines.c, we see that the corresponding code inside the loop is given by:
.L6: fnstcw WORD PTR [%ebp-14] fld DWORD PTR [%ebp-20] mov DWORD PTR [%esp], %ebx add %ebx, 1 mov DWORD PTR [%esp+8], %edi movzx %eax, WORD PTR [%ebp-14] mov %ah, 12 mov WORD PTR [%ebp-16], %ax fldcw WORD PTR [%ebp-16] fistp DWORD PTR [%esp+4] fldcw WORD PTR [%ebp-14] call put_pixel cmp %esi, %ebx fld DWORD PTR [%ebp-20] fadd DWORD PTR [%ebp-24] fstp DWORD PTR [%ebp-20] jge .L6 .L7:
The compiler generated a rather long series of instructions because it tries to enforce 32-bits precision (because the internal floating point registers aren’t 32 bits but 80!) as well as dealing with the conversion of float values to integer. Would the CPU have been capable of SSE, the compiler might have generated code using the cvttss2si instruction. This instruction that converts a scalar single precision float into an integer. Since this instruction uses the XMM registers, the code is greatly simplified because there is no need to worry about precision; floats are stored as 32 bits in XMM packed registers. All that to say that all this seems like a lot of code just to perform y+=m and truncating.
Jack Bresenham, in 1965, came up with an algorithm using only integer arithmetic to draw a line of arbitrary slope [1]. Bresenham algorithm will loop on the 

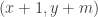

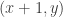

The derivation is quite convoluted and relies differential equations, implicit forms, and you can find a (still somewhat sketchy) demonstration demonstration here. You can find the complete demonstration in [2].
Again, without loss of generality, we will consider only slopes 
int dx=x2-x1;
int dy=y2-y1;
int d=2*dy-dx;
int e=2*dy;
int ne=2*(dy-dx);
int x=x1;
int y=y1;
for (x=x1;x<=x2;x++)
{
put_pixel(x,y,color);
if (d<=0)
d+=e;
else
{
d+=ne;
y++; // sign?
}
}
Which generates the following machine code:
.L21:
add %edi, DWORD PTR [%ebp-16]
add %esi, 1
add %ebx, 1
cmp DWORD PTR [%ebp+16], %ebx
jl .L24
.L20:
mov %eax, DWORD PTR [%ebp+24]
mov DWORD PTR [%esp+4], %esi
mov DWORD PTR [%esp], %ebx
mov DWORD PTR [%esp+8], %eax
call put_pixel
test %edi, %edi
jg .L21
add %edi, DWORD PTR [%ebp-20]
add %ebx, 1
cmp DWORD PTR [%ebp+16], %ebx
jge .L20
.L24:
## exits function
This code is simple but has conditional jumps within the main loop —for a total of three if you count the loop itself. On processors with bad, or no, branch prediction, or deep pipelines, the code yields sub-optimal performance. Every time a branch is mis-predicted, there’s a definite performance penalty. To avoid branching, we could try to transform Bresenham’s algorithm to a branchless algorithm (that is, except for the main loop that cycles from 

One possibility is to use the machine specific integer types to do all the work for us. Using the standard C library <stddint.h> header that provides types such as int16_t, we can create a fixed point number, one that is friendly to the machine’s natural register sizes. On 32 bits x86, those are 16 and 32 bits registers. On a 64 bits machine, we could still use 32 and 16 bits (and I’ve already explained why).
So let us define a fixed point number as the union of a 32 bits int and of two 16 bits integers that will hold, respectively, the fractional part and the integer part of the number. Note that on x86 computers, the memory layout is little endian, so one would have to reverse the declaration of lo and hi on a big endian machine. The declaration could be something like:
typedef
union
{
int32_t i;
struct
{
int16_t lo; // endian-specific!
int16_t hi;
};
} fixed_point;
The only thing we need, is to compute the slope
fixed_point y;
int x;
int32_t m=((int32_t)(y2-y1)<<16)/(x2-x1); // slope as fixed point
y.i=y1<<16; // convert to fixed point
for (x=x1;x<x2;x++,y.i+=m)
put_pixel(x,y.hi,color);
Only the integer part of the fixed point is used to call put_pixel. The whole fixed point number, however, is used to incrementally add the slope, m, to y. The trick here is that the integer .i that holds the fixed point number can be operated upon as is, and, for addition, adding two 32 bits integers that hold each a fixed point number yields a correct fixed point number. This allows the compiler to generate, compile-time, much simpler code that what one would have thought:
.L16: lea %esi, [%edi+%esi] .L13: mov %eax, DWORD PTR [%ebp+24] mov DWORD PTR [%esp], %ebx add %ebx, 1 mov DWORD PTR [%esp+8], %eax mov %eax, %esi sar %eax, 16 mov DWORD PTR [%esp+4], %eax call put_pixel cmp DWORD PTR [%ebp+16], %ebx jge .L16
We can add rounding to make sure the pixels drawn are, as with Bresenham’s algorithm, always as close as possible to the “true” line from
fixed_point f;
int x;
int32_t m=((int32_t)(y2-y1)<<16)/(x2-x1);
f.i=y1<<16;
for (x=x1;x<=x2;x++,f.i+=m)
{
fixed_point g=f;
g.i+=32767;
put_pixel(x,g.hi,color);
}
and generates the following:
.L16: lea %esi, [%edi+%esi] .L13: mov %edx, DWORD PTR [%ebp+24] lea %eax, [%esi+32767] sar %eax, 16 mov DWORD PTR [%esp], %ebx add %ebx, 1 mov DWORD PTR [%esp+4], %eax mov DWORD PTR [%esp+8], %edx call put_pixel cmp DWORD PTR [%ebp+16], %ebx jge .L16
Which doesn’t differ much from the other version.
*
* *
Now it’s time to check the resulting speeds of the implementations. I have included results for a 32 bits machine, an Athlon XP 2000+ (1.66GHz) and a 64 bits machine, a AMD64 Athlon 4000+ (2.25GHz). The first machine is incapable of SSE, while the second is limited to SSE2. In both cases, I used similar compilation options:
gcc -fno-inline-functions -O3 -mX lines.c -o lines
with X being either 32 or 64 (bits) depending on the machine. The test was to draw a line with different offsets but the same length, about 200 pixels long. The buffer was prefetched in cache to avoid spurious fluctuations. In 32 bits mode, we get:

Timing results, 32 bits Athlon XP 2000+
The naïve algorithm in float averages 4.81 µs, Bresenham’s algorithm averages at 1.84 µs, my fixed point variation at 1.74 µs. The Fixed point implementation runs about 5% faster. Which isn’t all that much, but still better than Bresenham’s; and much better than the naïve version using mixed floats and integers.
The situation is similar on the 64 bits machine, but the advantage of fixed point vanishes. Both methods takes very similar times: fixed point averages at 0.85 µs and Bresenham 0.84 µs, a difference of about 1%. However, the naïve implementation is still very far behind, at 2.96 µs.

Timing results, 64 bits AMD64 4000+
*
* *
Although the testing is far from exhaustive, the results indicates that the fixed point algorithm is very efficient. I would guess that as you go down to simpler processors, the more efficient it will be. First, it has fewer branches than Bresenham’s algorithm. Second, it is quite possible that a clever use of the instruction set and registers yield code that is much more efficient than what gcc generates—although, I admit, it seems quite efficient at times.
[1] Jack E. Bresenham — Algorithm for computer control of a digital plotter — IBM Systems Journal, Vol. 4, No.1, January 1965, pp. 25–30 (pdf, subscription needed)
[2] James D. Foley, Andries van Dam, Steven K. Feiner, John F. Hughes — Computer Graphics: Principles and Practice — Addison-Wesley, 1995.

Nice. Might come in handy some day. Thanks.
thanks,
helpfully
[…] of doing a ‘free’ scaling is to use a trick similar to what I used for an alternative line algorithm. That is, we’ll use the language to have a shift free […]
[…] course there are better ways of drawing a line between two points. Interpolation may be used to fill a continuum or only to get […]
Actually Brez’s algorithm is just a specialised version of a form of linear interpolation (sometimes refferred as digital differential).
Also , the algorithm can be used for much more than just drawing lines. I have found it useful for animation, image scaling etc. I had a much improved ‘splinner’ for Wolfenstein/Doom style games that was used to draw the ‘splines’ when renderring textures (it was faster than original and allowed you to get as close as possible to walls without distortion etc). A generalised version of the algorithm is presented below that removes all multiplication/ division, takes care of all quadrants and doesent care which point is given first. It take a callback back and so can be treated as a libray funtion for anything, to draw lines you just pass in a callback to your draw pixwel function.
You may need to copy it out to read it…
#define SWAPINT(a,b) a^=b; b=a^b; a=a^b
/** Bresenham line algorithm.
*
* @return 0 if completed, any non-zero value indicates callback aborted run.
*
* @param cb – Pointer to callback function.
* @param x1,y1 – Start point.
* @param x2,y2 – End point.
*
* @note This function calculates all the integral points on a line
* and passes these back through a callback. The callback
* function is called for each distinct point on the line.
* The callback function can return a non-zero value to halt the
* algorithnm at any time.
*
* This is my own version which appears to work in all situations.
* I looked at lots of different versions on-line and they all had minor quirks.
* Basic info from:
* http://www.gamedev.net/page/resources/_/reference/programming/140/283/
* bresenhams-line-and-circle-algorithms-r767
* and from Pascal program I wrote in 1981!
*/
int TBres( int (*callback)(int x, int y), int x1, int y1, int x2, int y2)
{
int x, y, d, xdelta, ydelta, yinc=1, swapped=0, rc=0;
xdelta = abs(x2-x1)+1;
ydelta = abs(y2-y1)+1;
if (ydelta > xdelta) // We need x delta to be the bigger of the two…
{
SWAPINT( xdelta, ydelta);
SWAPINT( x1, y1);
SWAPINT( x2, y2);
swapped = 1;
}
if (x2<x1) // We have to travserse the line from lower to higher x…
{
SWAPINT( x1, x2);
SWAPINT( y1, y2);
}
if (y2<y1) // If slope is negative y increment is -1.
yinc = -1;
y = y1;
d = ydelta;
// Main loop…
for (x=x1; x=xdelta)
{
y += yinc;
d -= xdelta;
}
d += ydelta;
}
return rc;
}
Very weird, in previous reply, a chunk of code was not posted, here it is again…
int TBres( int (*callback)(int x, int y), int x1, int y1, int x2, int y2)
{
int x, y, d, xdelta, ydelta, yinc=1, swapped=0, rc=0;
xdelta = abs(x2-x1)+1;
ydelta = abs(y2-y1)+1;
if (ydelta > xdelta) // We need x delta to be the bigger of the two…
{
SWAPINT( xdelta, ydelta);
SWAPINT( x1, y1);
SWAPINT( x2, y2);
swapped = 1;
}
if (x2<x1) // We have to travserse the line from lower to higher x…
{
SWAPINT( x1, x2);
SWAPINT( y1, y2);
}
if (y2<y1) // If slope is negative y increment is -1.
yinc = -1;
y = y1;
d = ydelta;
// Main loop…
for (x=x1; x=xdelta)
{
y += yinc;
d -= xdelta;
}
d += ydelta;
}
return rc;
}
Very bizzare… when I post reply code dissapears…try again, if this doesent work and you want the code email me at tim_ring AT yahoo.com…
Just the main loop…
// Main loop…
for (x=x1; x=xdelta)
{
y += yinc;
d -= xdelta;
}
d += ydelta;
}
(As a first-time poster, your posts needed my approval. Here, everything shows up now.)
And yes, I have used a variation of Bresenham’s for image scaling without color interpolation (or resampling) a long time ago. I also used something (in the time of 10MHz CPUs) based on remainders to double a pixel once in a while for scaling up images.
Thanks, Here is actual code I posted….
int TBres( int (*callback)(int x, int y), int x1, int y1, int x2, int y2) { int x, y, d, xdelta, ydelta, yinc=1, swapped=0, rc=0; xdelta = abs(x2-x1)+1; ydelta = abs(y2-y1)+1; if (ydelta > xdelta) // We need x delta to be the bigger of the two... { SWAPINT( xdelta, ydelta); SWAPINT( x1, y1); SWAPINT( x2, y2); swapped = 1; } if (x2<x1) // We have to travserse the line from lower to higher x... { SWAPINT( x1, x2); SWAPINT( y1, y2); } if (y2<y1) // If slope is negative y increment is -1. yinc = -1; y = y1; d = ydelta; // Main loop... for (x=x1; x=xdelta) { y += yinc; d -= xdelta; } d += ydelta; } return rc; }Very strange how it just dropped the centre code from the loop. The main loop is quite efficent and versions of this code ended up as x86 code in my (very old) Wofenstein clone. Thanks again, Tim.
From: “Harder, Better, Faster, Stronger” To: tim_ring@yahoo.com Sent: Tuesday, July 28, 2015 2:37 PM Subject: [New comment] Faster than Bresenham’s Algorithm? #yiv4308474562 a:hover {color:red;}#yiv4308474562 a {text-decoration:none;color:#0088cc;}#yiv4308474562 a.yiv4308474562primaryactionlink:link, #yiv4308474562 a.yiv4308474562primaryactionlink:visited {background-color:#2585B2;color:#fff;}#yiv4308474562 a.yiv4308474562primaryactionlink:hover, #yiv4308474562 a.yiv4308474562primaryactionlink:active {background-color:#11729E;color:#fff;}#yiv4308474562 WordPress.com Steven Pigeon commented: “(As a first-time poster, your posts needed my approval. Here, everything shows up now.)And yes, I have used a variation of Bresenham’s for image scaling without color interpolation (or resampling) a long time ago. I also used something (in the time of” | |
WordPress isn’t all that smart with code. You may enclose your code between [ sourcecode language=”thelanguage”]…code in thelanguage…[ / sourcecode] (without the spaces).
Shouldn’t y(x) = y1 + m.(x – x1)? Otherwise we are ignoring the translation along the x-axis.
Yes indeed! Fixed.
on my recent intel cpu and visual studio 2019 compiler fixed point is a little faster then naive algorithm and bresenham is the slowest. I think float to int conversion is way more efficent than a branch if for an 2020 intel cpu + vs2019 compiler combination. Good article, brilliant!
Fixed point is integer-only, so it should’nt be a problem for a modern CPU. Floats are also really fast on my 3900X. I wonder how much SIMD we could push into this algorithm?
Sorry for the delayed response. It took some time to find article related to SIMD. How do you write SIMD code that could run accross different plateform. Do you think ispc a good idea?
I’d be relying on a vectorizing compiler. But I don’t know how good the compilers are at vectorizing. G++ is better than it used to be, ICC was good, but I don’t really have quantitative assessments.