QuickSort, due to Hoare, is one of the best comparison-based sorting algorithms around. There are a number of variations, but the vanilla QuickSort does a great job… most of the times.

Indeed, there are occasions where QuickSort leaves its expected 
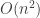
Let us consider this basic C++ implementation of QuickSort:
template <typename T>
int quicksort( T array[], int lo, int hi)
{
int x=lo,
y=hi;
const T p = array[(x+y)/2];
do
{
while (array[x]<p) x++;
while (p<array[y]) y--;
if (x<=y)
{
std::swap(array[x], array[y]);
x++;
y--;
}
}
while (x<y);
if (lo<y) quicksort(array,lo,y);
if (x<hi) quicksort(array,x,hi);
}
This version picks the pivot in the middle of the sub-array to perform partition. It creates two sub-arrays out of the currently considered sub-array and calls itself on the sub-arrays if they contain more than one element. Applying this procedure recursively eventually leads to a completely sorted array, and QuickSort succeeds.
So let us look at how this partition methods really works. It starts by picking a pivot value, p, in the middle of the partition. It has two indexes, x and y that are initially at either end of the sub-array. The goal is to shuffle the elements around so that all elements on the left are smaller than the pivot, and all elements on the right are larger than the pivot. To so so, we advance x while the element it points to is smaller than the pivot. The loop ends when it finds an element larger or equal to the pivot. The same is done in reverse for y where it backs up while it points to an element that is larger than the pivot. When both x and y stop moving, both point to an element that should be on the other side of the array, so we swap the elements they point to, and move x and y to the next elements to examine. We are done when eventually x and y meet somewhere in the middle of the array. At that moment, we have two sub-arrays and we call recursively QuickSort on both.
Normally, x and y meet somewhere in the middle, so both sub-arrays are roughly of the same size, that is, 

But what if something goes wrong with the partition and we somehow get very bad partitions? Something like 

If you pick the pivot in the middle, it’s rather hard to reach the worst case, but we’ll see how we can do it. Let us start with an array already sorted in increasing order. Suppose that, instead, we pick the pivot as the first element of the sub-array. The partition algorithm, as shown above, will create two partitions: one of size one with the pivot value, and another of size 
Doing so, we get a complexity of 
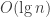
But how? It would be necessary that every chosen pivot is the smallest value in the sub-array, causing the partition to shove it leftmost and shifting all the left-side values one up. Can we do that? Sure! Consider:
void evil_init( int array[], int nb_items )
{
for (int i=0;i<nb_items;i++) array[i]=i;
for (int j=nb_items-1;j>-1;j--)
{
int p=(nb_items-1+j)/2;
std::swap(array[j],array[p]);
}
}
This initialization procedure reverses QuickSort’s sort case to produce an array that will be quite hard to sort.

The evil_init function animated. Each frame is one swap. Click to animate.

Adding an iteration counter in QuickSort will let us monitor just bad it gets. We can also test different types of array: already sorted in increasing order, random, and “evil”.
| size | 1 | 10 | 100 | 1000 | 10000 | 100000 |
 |
0 | 33 | 664 | 9966 | 132877 | 1660964 |
| Increasing | 2 | 31 | 606 | 9009 | 125439 | 1600016 |
| random | 2 | 41 | 852 | 13187 | 177715 | 2237943 |
 |
1 | 55 | 5050 | 500500 | 50005000 | 5000050000 |
| Evil | 2 | 59 | 5054 | 500504 | 50005004 | 5000050004 |
For the random arrays, I used the average, rounded to the nearest integer, of 1000 runs. Looking at the table we should see at least three things.
The first is that sorting an increasing array gives very close to the expected
The second is that the evil array pushes QuickSort into its worst case with exactly the expected complexity! Indeed, the complexity is almost exactly
The third, that actually surprised me, is how far QuickSort can go on random arrays. If you examine the table, you’ll see that the number of iterations for the randomly initialized arrays is much higher than the expected 
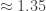
*
* *
So, even if picking the pivot in the middle, when possible, will give us some protection against an already sorted array, it is still possible to get the absolute worst case using a maliciously initialized array, as created by the evil_init function. Probably randomizing the choice of the pivot to be somewhere around the center of the current partition would offer some additional protection, but one could always come up with a method, not unlike evil_init, to construct a malicious array that defeats the randomized pivoting, albeit probably not as well.
*
* *
The QuickSort animation used at the top of this post comes from the WikiMedia Commons, for which, I must say, I have the greatest respect. Please support Wikipedia.
1 In fact, it is dead on. The

Most library implementations (including libc, from what I’ve read) use a completely randomized pivot for this very reason. Although the middle of the array should be a safe choice, it allows a malicious user to make a DoS attack much more successful just by crafting the correct input.
It’s quite well known that the number of comparison operations in quicksort with randomized input is larger than n*log2(n), it’s roughly 1.39*n*log2(n), according to Wikipedia (http://en.wikipedia.org/wiki/Quicksort#Average_complexity), so your results should not be surprising.
Social comments and analytics for this post…
This post was mentioned on Reddit by stordoff: I thought that it was well known that QuickSort has a pathological case if you pick the middle item as the pivot. There are a few ways of minimise the chance of it: 1) Pick the pivot randomly (some overhea…
[…] the pivot in the middle of the current sub-array reduces this risk quite a lot (and it would take quite an evil array to push it back to behavior). Furthermore, each time select is called on the array,it gets more […]