The game is different whether we consider external data structures—that live partially or totally on disk or over the network—or internal data structures residing entirely in local memory. For one thing, none of the courses I had on data structures I had really prepared me to deal adequately with (large) external data structures; it was always assumed that the computer’s memory was somehow spacious enough to hold whatever data you needed.

However, when you’re dealing with files, you can’t really assume that you can access random locations to read, write, or exchange data at low cost, and you have to rethink your algorithms (or change plans altogether) to take the cost of slow external media into account. Sometimes an algorithm that doesn’t look all that useful in main memory suddenly makes more sense in external memory because of the way it scans its data. One of these algorithms is the Shellsort.
No, Shellsort didn’t get its name from some crustacean/molluscean metaphor for sorting, but from Donald L. Shell, its inventor. Shellsort was published in 1959, [1], about two years before Hoare‘s Quicksort [2].
Shellsort is an extension of the infamous Bubblesort but instead of comparing and exchanging, if need be, only immediately neighboring cells, it relies on an increment sequence (or gap sequence) to compare-exchange cells that are further apart and eventually sort the array. The increment sequence is a sequence that starts mandatorily with 1 and is strictly increasing. For example, 
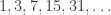

So let us continue with the description of the sorting procedure. The basic step of the algorithm is the same as with Bubblesort, that is, we scan the array from bottom to top and compare-exchange neighboring elements. With Bubblesort, we consider only immediately neighboring cells, t[i] and t[i+1], and we bubble through the array as many times as necessary, until we can scan the array without performing an exchange. That is, something like:
bool touched;
do
{
touched=false;
for (int i=0;i<n-1;i++)
if (t[i]>t[i+1])
{
std::swap(t[i],t[i+1]);
touched=true;
}
} while (touched);
This sorting procedure is notoriously bad. If a cell contains a value that is very far from its final (sorted) position, you can do up to 
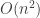

Shellsort, while doing essentially the same thing, tries to move values around faster using the increment sequence. Instead of comparing only t[i] and t[i+1], it will compare t[i] and t[i+inc], for some value of inc. It repeats the main loop with inc until no more swaps are performed. With Bubblesort, that would mean we are done (because increments are 1 and now the array is completely sorted) but if we have an increment greater than 1, the array is in a semi-sorted state (in fact, it is inc-sorted). With Shellsort, if the increment is not already 1, we decrease it significantly—the best sequences are geometric-looking—and repeat the bubbling until, again, no swaps are performed. And we decrease the increment again, and bubble again, and repeat the whole process until the increment eventually reaches one. When the increment is 1, we do a last Bubblesort (but most elements are almost sorted already) and the algorithm terminates.
Code speaks, and the implementation (essentially the one presented in [3]) is as follows:
////////////////////////////////////////
//
// Shell Sort
// http://en.wikipedia.org/wiki/Shell_sort
//
template <typename T>
void shell_sort(T items[],
size_t nb_items,
const size_t increment_sequence[],
uint64_t & scans, // performance counter
uint64_t & swaps // performance counter
)
{
scans=0;
swaps=0;
if (nb_items)
{
// points to the current
// increment in sequence
//
int inc_index=0;
// find the first increment
// smaller than the array.
//
while (increment_sequence[inc_index]>nb_items) inc_index++;
// perform shell sort
//
while (increment_sequence[inc_index])
{
bool touched;
const size_t this_inc=increment_sequence[inc_index];
do//while(touched)
{
touched=false;
scans+=nb_items-this_inc;
for (int i=this_inc; i < nb_items; i++)
if (items[i]<items[i-this_inc])
{
std::swap(items[i],items[i-this_inc]);
swaps++;
touched=true;
}
} while (touched);
inc_index++;
}
}
}
A first guess for the sequence would be to use a power-of-two sequence or (Shell’s initial guess) the sequence 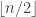
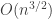
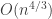
For the purpose of demonstrating the influence of the increment sequence, we chose the following sequences:
- Sedgewick‘s A003462
- Sedgewick’s A036562
- Sedgewick’s (or Sedgewick-Incerpi) A036569,
- Pigeon’s A055875, that I submitted in august 2000,
- Pigeon’s A055876, that I also submitted in August 2000 (the best sequence for a while, at least as far as I know)
- Powers of 2,
, that isn’t all that good,
- Powers of 2 minus 1,
, that performs rather well,
- Fibonacci, A000045,
- Ciura’s A102549, the best known sequence so far, from 2001
- “Fat Fibonacci” A154393
The test arrays, increasingly larger (1000 to 10000, steps of 1000), are initialized with uniform random values in the range 0 to RAND_MAX, and each test is repeated 50 times, with different random values. However, the same random arrays are used for all tests; that is, it is the same initial buffers of size 1000 for all sequences so that the increment sequences are compared fairly on the same random data.
The first result concerns the number of scans, or compares, performed by Shellsort given an increment sequence.

You see that Ciura’s sequence A102549 is the sequence that asks for the least number of compares, followed by A055876. Fibonacci and powers of 2 perform the worst, again maybe counter-intuitively.
The picture is slightly different when we compare the number of swaps by sequence. The power of 2 sequence now doesn’t perform all that bad; there are worse sequences.

However, the best way to compare the performance of the sequences would be to use a combined cost model where reading and exchanging have different costs, one cost for reading an entry, and another to rewrite it; let us feign that comparing (two reads) and exchanging (two reads, two writes) cost the same. This yields the following graphic:

where the three best sequences are Segdewick’s (or Sedgewick-Incerpi) A036569, the sequence A055876, and Ciura’s A102549.
*
* *
The complexity analysis of Shellsort is far from trivial and Ciura [4] resorted to essentially an empirical method to derive his best sequences and conjectures that it might be optimal. Ten years ago, I must admit that I also took an educated guess and a bit of empirical evidence to propose A055876, but it turns out that this sequence isn’t all that bad either.
[1] D. L. Shell — A High-Speed Sorting Procedure — Comm. ACM, v2(7), (1959) p. 30–32
[2] C. A. R. Hoare — Quicksort — The Computer Journal, v5(1) (1962) p. 10–15
[3] R. Sedgewick — Analysis of Shellsort and Related Algorithms — 4th Annual European Symposium on Algorithms (1996) LNCS# 1136, p. 1–11
[4] M. Ciura — Best Increments for the Average Case of Shellsort — 13th Int. Symposium on Fundamentals of Computation (2001) LNCS# 2138, p. 106–117


Interesting, although I kind of lost the connection to the motivation for shell sort, i.e. data on disk.
Also, sea shells are mollusks, not crustaceans :-)
The connection is the way Shellsort scans the array; at all time you can have a small working set in memory, and only two read/writes locations, corresponding to the two “pages” were compare-exchanges occur, each moving in the same direction, which is probably cache-friendly (and classical IO-device friendly; of course, less of a consideration with SSD). You can have that with other sorts, say, Quicksort and Lomuto’s partition method; but it is likely that it much simpler to transform Shellsort to be page-based (as minimizing IO would certainly require) than Quicksort.
It would be interesting to actually compare the various disk-based sorting algorithms, but I never found a decent monograph on the subject. All I found is deliciously obsolete stuff on ISAM and punch cards… If you know of a modern reference on the topic, let me know.
(also, “shellfish […] including various species of molluscs, crustaceans, and echinoderms” (from wikipedia) :p)
Did you use any extension of Ciura’s sequence and what is the best way to extend it? Reading Wikipedia I find the recommendation to extend it by h_k = floor(2.25 h_k-1).
No, I did not. I suppose one could evolve the sequence from many examplars (with something like genetic programming, say), or push the analysis of Shell sort much further than what was previously done. In a way, it may seem as wasted effort, because, other than satisfying one’s own curiosity, solving the best sequence for a polynomial-time sort isn’t all that useful— is much better than
is much better than  , for large
, for large  .
.
But, you know, I’ve thought of doing so anyway ;)
1) Plotting (no. of compares) / (optimum no. compares) is a very good way to compare sort algorithms, or indeed various gap increment sets with shellsort. Wikipedia on shellsort helpfully points out that the optimum no. of compares to sort N items is log2( N! ). Ergo, on your vertical axis, plot (actual no. compares) / ( log2( N!) ).
Optimum no. of swaps is less helpful, as that’s just N-1.
2) Are you implying that shellsort has time (or cost) O(n^ 4/3) or even O(n^ p) where p is greater than 1? I’ve done trials with shellsort up to 250,000 items, with Ciura’s sequence and others, and some sequences I’ve invented, and calculated the implied value of p (=log(no. compares)/log(N)) and it drops monotonically, getting down to about 1.2 for N=250,000
I tried sequences very similar to power-of-2 sequences.
1) 2^n
2) 2^n + 1
3) integers as close as possible to 2^n, but ensuring that no increments had any common factors greater than 1
No. 1 took vastly more compares.
No. 2 took substantially fewer compares, not just by a factor, but as if there were a reduction from a power law (e.g. N^1.5) to a lower power law (e.g. N^1.35 or similar).
No. 3 was best of all. The number of compares (up to N of around 250,000) took maybe 30% more compares than Ciura’s sequence.
I can guess at why mutually prime increments (except maybe the very smallest ones) presents an advantage, as you avoid testing the same location successively.
I don’t see that it’s proven that shellsort is slower than O(nlogn)
That’s why it’s still worth exploring better increment sequences.
I can think of a reason why mutually prime increments are better: essentially, you avoid making comparisons where you already know the answer. If you make such a comparison, you’re wasting effort, because you’re finding out something you already know.
Suppose you use a gap of 2, then a gap of 1. With items A, B, C, D, E, you have already compared A and C, C and E, etc., ensuring A<C<E and B<D.
Now you use the gap of 1. Suppose the insertion sort compares A with B and realises that B<A, so it swaps them, leaving the list as:
BACDE
Next, insertion sort compares A with C, but the previous sort (with gap 2) has already done that, ensuring that A<C, so the sort is making a comparison which is useless, because we already know that A<C. That's a waste of effort, so the code takes longer than necessary.
Simple ratios between gap lengths will make this kind of thing happen often.
I’ve found this sequence similar to Marcin Ciura’s sequence:
1, 4, 9, 23, 57, 138, 326, 749, 1695, 3785, 8359, 18298, 39744, etc.
For example, Ciura’s sequence is:
1, 4, 10, 23, 57, 132, 301, 701, 1750
This is a mean of prime numbers. Python code to find mean of prime numbers is here:
import numpy as np def isprime(n): ''' Check if integer n is a prime ''' n = abs(int(n)) # n is a positive integer if n < 2: # 0 and 1 are not primes return False if n == 2: # 2 is the only even prime number return True if not n & 1: # all other even numbers are not primes return False # Range starts with 3 and only needs to go up the square root # of n for all odd numbers for x in range(3, int(n**0.5)+1, 2): if n % x == 0: return False return True # To apply a function to a numpy array, one have to vectorize the function vectorized_isprime = np.vectorize(isprime) a = np.arange(10000000) primes = a[vectorized_isprime(a)] #print(primes) for i in range(2,20): print(primes[0:2**i].mean())The output is:
4.25
9.625
23.8125
57.84375
138.953125
326.1015625
749.04296875
1695.60742188
3785.09082031
8359.52587891
18298.4733887
39744.887085
85764.6216431
184011.130096
392925.738174
835387.635033
1769455.40302
3735498.24225
The gap in the sequence is slowly decreasing from 2.5 to 2.
Maybe this association could improve the Shellsort in the future.
The indentation of the source code is broken, so here is a link on stackoverflow web site comment:
https://stackoverflow.com/a/46119333/7550928
There, I fixed the indentation.
That’s actually interesting. I wonder if we could solve somewhat systematically for “the best sequence” under specific assumptions… That’s something we should look into.
Dear Steven,
I’ve compared sorting times for classical Shellsort, Ciura’s empirical gap sequence and gaps for mean primes and there is no big difference in sorting time for Ciura’s gaps and mean primes gaps. At least for Python. I should rewrite the code on C++ for better understanding and for sorting arrays bigger that 1 million numbers.
More over, if you take a ratio between neighbors in mean primes sequence and create a graph from them, you’ll see that from the 3rd point this graph could be approximated with polynomial function. So there is no need to calculate all these means from prime number sequence. We could find this sequence (4, 9, 23, 57, 138, etc.) in no time using polynomial approximation.
I’ll play around with this gap sequence and send you results at the end of this week or at the beginning of the next week.
1. Try to find a polynomial approximation.
2. Compare sorting times for unsorted, partly sorted and inverted sorted arrays. On Python and C++.
3. Find number of comparisons for this gap sequence.
I have spent a great deal of time exploring shellsort and what I have been able to discern is that no one has yet come up with (or, at least, published) an algorithm that describes the interaction between the data sequence and the gap sequence as well as the interaction between the gaps in the sequence.
In the absence of such an algorithm the most accomplished (and famous!) computer scientists of our time resort to
1. the Monte Carlo method devising formulas to produce gap sequences
2. testing the sequences devised on their own sets of random data
3. touting their results as at least better than all the previous ones without the caveat that “my gaps run better on my random data than your gaps run on your random data”
There are many well-meaning suggestions concerning what a “good” gap sequence “should” look like (perhaps using some some sort of formula) and what are “good” individual values (a mix of odd, even and/or prime values). Are they based on fact or on “sound” assumptions.
Maybe I have missed something but doesn’t the absence of a definitive algorithm reduce most if not all of the discussion about shellsort to random shots in the dark?
One thing I have noticed (that has also led me astray) in my own work is that “random data” usually introduces issues that distort the results. Testing different gap sequences on the same set of random data sounds like a sound approach but how can you be sure that your random data is gap sequence neutral?
The only really neutral data isn’t random: it is the set of all possible combinations of n values i e n! combinations. Exhausts me just thinking about it …
It seems the discussion can’t even agree on if the definition of shellsort’s best case is O(n) or O(n log(n)). Newbies come up with the former, old hands with the latter. Who is right? If you assume you are insertion sorting a data vector of (n=) 6 values the best case will be 5 comparisons (or n-1). If you shellsort it with gaps 4 and 1 the first gap will cause 2 comparisons (n-4) and the second 5 (n-1) or 7 in total (2*n-(4+1)). “2*n” looks suspiciously not like “n log(n)”. A longer sequence of gaps (for a longer data vector) might yield a 3*n, 4*n, 5*n or even higher component but does that make it n log(n)?
Is a shellsort reset in order?
Shell sort isn’t that much of a good sort, everybody agrees on that. It is mostly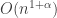 (with
(with  ), which makes it polynomial time (Pratt came up with sequence that makes it
), which makes it polynomial time (Pratt came up with sequence that makes it  , but the sequence isn’t strictly decreasing). In any case, Shell sort is not
, but the sequence isn’t strictly decreasing). In any case, Shell sort is not 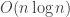 . Why is it polynomial?
. Why is it polynomial?
Well, the key is to analyse how we loop until nothing has moved with gap d. We repeat at most times so that an item can move from the top to the bottom, but each loop is
times so that an item can move from the top to the bottom, but each loop is  . Now, if
. Now, if  is constant for each pass, it must be 1, and you get… bubble sort.
is constant for each pass, it must be 1, and you get… bubble sort.
Now, since depends on $n$ and changes, the complete analysis is tricky. First because we must account for the changing
depends on $n$ and changes, the complete analysis is tricky. First because we must account for the changing  (with the specific sequence). Second because we must take in consideration all possible sorting sequences. So basically, we must account for all possible permutations of orderings, and average over that. That usually lead to quite intricate recurrences that are hard to solve. Worst, we mix a probability distribution over these orderings…
(with the specific sequence). Second because we must take in consideration all possible sorting sequences. So basically, we must account for all possible permutations of orderings, and average over that. That usually lead to quite intricate recurrences that are hard to solve. Worst, we mix a probability distribution over these orderings…
Hi Steven and thanks for your reply!
I think it is fair to modify your first sentence to read
“Given the current level of understanding of how shellsort works, there is a general agreement that shellsort isn’t that much of a good sort.”
In the same vein, also your third sentence
“… shellsort is not considered to be O(n log(n)) …”
Current average and worst cases are estimated based on that level of understanding and have evolved over many years from downright poor to mediocre. It is not unreasonable to assume they will improve as more is understood about shellsort. I see it as unacceptable that current estimates should be viewed as fact. As I pointed out, it can be argued that shellsort’s best case isn’t O(n log(n)) but rather O(n).
Sure, Pratt came up with a polynomial time given one sequence and O(n^1.5) with another. He was preceeded by Shell whose sequence yielded O(n^2). Suceeded by Sedgwick whose sequence gave O(n^4/3). Which simply proves my point that estimates are evolving but perhaps not based on an especially solid foundation of knowledge.
Assumptions underpinning current work on shellsort seem unproven and therefore questionable, probably well-meaning but still questionable. As you say, “everybody agrees” and almost “everyone continues to build” based on that: Shell started the ball rolling, followed (in the same vein) by Pratt, Sedgwick, Knuth, Ciura etc.
Actually, I think the analysis is getting way better than just mediocre. Sedgewick published a survey on the problem (1996 if I remember correctly) ( http://thomas.baudel.name/Visualisation/VisuTri/Docs/shellsort.pdf ). It shows that the lowerbound, for any sequence, is polynomial (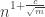 , for
, for  items and
items and  passes,
passes,  ).
).
Also,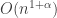 and
and  entertain a complex relationship. They’re often comparable in magnitude, depending on
entertain a complex relationship. They’re often comparable in magnitude, depending on  and
and 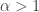 . In the following graph, you can see that Pratt’s sequence wins over
. In the following graph, you can see that Pratt’s sequence wins over  for problems of size
for problems of size 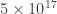 . So you’re likely better off with the
. So you’re likely better off with the 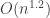 sequence.
sequence.
The O(n(log n)²) sequence still works when itself sorted (in fact, any order where all the gaps 2n and 3n occur before n). However, it also has O(n(log n)²) best case, and this sequence also works for comb sort, avoiding the redundant comparisons of Shell sort with this sequence.