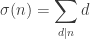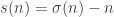In a previous episode, we looked at how we could use random sampling to get a good estimate of 

Can we increase the precision of the estimate by using a better method? Maybe something like numerical integration?
In a previous episode, we looked at how we could use random sampling to get a good estimate of
Can we increase the precision of the estimate by using a better method? Maybe something like numerical integration?
 1 Comment |
1 Comment |  Mathematics, programming | Tagged: double, float, ha ha, Integral, π, machine precision, numerical integration |
Mathematics, programming | Tagged: double, float, ha ha, Integral, π, machine precision, numerical integration |  Permalink
Permalink
 Posted by Steven Pigeon
Posted by Steven Pigeon
I know of no practical use for Amicable numbers, but they’re rather fun. And rare. But let’s start with a definition. Let 
with 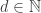
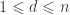
Now we’re ready to define amicable numbers!
Amicable numbers: Two numbers, 
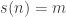

Given 

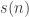


Leave a Comment » | algorithms, Mathematics | Tagged: amicable numbers, Ancient Greeks, Euler, Factorization, number theory, Prime numbers | Permalink
Posted by Steven Pigeon
We often start thinking about something, make some progress, and eventually realize it’s not going anywhere, or, anyway, the results aren’t very phrasmotic—certainly not what you hoped for. Well, this week’s post is one of those experiments.

So I was wondering, how can I compute the binomial coefficient, 
Leave a Comment » | algorithms, Mathematics, programming | Tagged: Binomial, Factorial, numerical method | Permalink
Posted by Steven Pigeon
In a city with orthogonal streets and regular city block, a party-goer leaves a bar and walks back home. His home is North East from the bar, 


1 Comment | Mathematics | Tagged: Binomial, bit, Bits, Drunkards, Encoding, Problème de l'ivrogne, Random Walk, Recurrence | Permalink
Posted by Steven Pigeon