I have been reading a lot of mathematical recreation books of late. Some in English, some in French, with the double goal of amusing myself and of finding good exercises for my students. In [1], we find the following procedure:
Take any number,  digits long, make this number
digits long, make this number  . Make
. Make 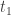 the number made of the sorted (decreasing order) digits of , and
the number made of the sorted (decreasing order) digits of , and 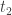 , the number made of the sorted (increasing order) digits of . Subtract both to get
, the number made of the sorted (increasing order) digits of . Subtract both to get  :
:  . Repeat until you find a cycle (i.e., the computation yields a number that have been seen before).
. Repeat until you find a cycle (i.e., the computation yields a number that have been seen before).
Jouette states that for 2 digits, the cycle always starts with 9, for 3 digits, it starts with 495, for 4 digits, 6174, and for 5 digits, 82962. For 2, 3, and 4 digits, he’s mostly right, except that the procedure can also reach zero (take 121 for example: 211-112=99, 99-99=0). For 5 digits, however, he’s really wrong.
Read the rest of this entry »




 Posted by Steven Pigeon
Posted by Steven Pigeon 
 . Are they hard to build? Fortunately, not really. Can we exploit the uniqueness of the hashed value to speed look-ups up? Yes, but it’s a bit more complicated.
. Are they hard to build? Fortunately, not really. Can we exploit the uniqueness of the hashed value to speed look-ups up? Yes, but it’s a bit more complicated.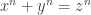
 . Well, guess what:
. Well, guess what: .
.