Python is a programming language that I learnt somewhat recently (something like 2, 3 years ago) and that I like very much. It is simple, to the point, and has several functional-like constructs that I am already familiar with. But Python is slow compared to other programming languages. But it was unclear to me just how slow Python was compared to other languages. It just felt slow.

So I have decided to investigate by comparing the implementation of a simple, compute-bound problem, the eight queens puzzle generalized to any board dimensions. This puzzle is most easily solved using, as Dijkstra did, a depth-first backtracking program, using bitmaps to test rapidly whether or not a square is free of attack1. I implemented the same program in C++, Python, and Bash, and got help from friends for the C# and Java versions2. I then compared the resulting speeds.
The eight queens puzzle consist in finding a way to place 8 queens on a 8×8 chessboard so that none of the queen checks another queen. By “checking”, we mean that if the other queen was of the opposing camp, you could capture it if it were your turn to play. So this means that no queen is on the same row, column, or diagonal as another queen. Using a real chessboard and pawns in lieu of queens, you can easily find a solution in a few seconds. Now, to make things more interesting, we might be interested in enumerating all solutions (and, for the time being, neglecting to check if a solution is a rotated or mirrored version of another solution).
The basic algorithm to solve the Eight queens puzzle is a relatively simple recursive algorithm. First, we place a queen somewhere on the first row and we mark the row it occupies as menaced. We also do so with the column and two diagonals. We then try to place a second queen somewhere on the second row, on a square that is menace-free, and mark the row, column, and diagonals of the new queen as menaced. And we proceed in the same fashion for other queens. But suppose that at the 
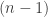
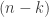
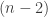
Because the algorithm proceeds depth-first and can rear back quite a bit in looking for new solutions, it is called a backtracking algorithm. Backtracking algorithms are key to many artificial intelligence systems like, well, chess programs.
So I wrote the program for the 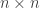
All implementations were compiled with all optimizations enabled (-O3, inlining, interprocedural optimizations, etc.). For C++, I used g++ 4.2.4, for C#, gmcs 1.2.6.0, for Java, gcj 4.2.4, Python 2.6.2, and, finally, Bash 3.2.39—all latest versions for Ubuntu 8.04 LTS, which doesn’t means that they’re the really latest versions.
So I ran all seven implementations with boards sizes ranging from 1 to 15 on a AMD64 4000+ CPU (the numbers are arbitrary; I wanted to get good data but also limit the CPU time spent as the time increases factorially in board size!). At first, the results are not very informative:

Results, Time, Linear Scale
As expected, all times shoot up quite fast, with, unsurprisingly, BASH shooting up faster, followed by the two Python implementations. At this scale, Java, C#, C++, C++-fixed (the constant-propagated version) all seems to be more or less similar. To remove the factorial growth (as even with a log plot the data remains rather unclear), I scaled all performances relative to the C++ version. The C++ version is therefore 1.0 regardless of actual run-time; for board size

Speed Ratio, Linear Scale
We can use a log-scale for the 

Speed Ratio, Log Scale
We see three very strange things. The first is Bash shooting up wildly. The second is that C# relative time goes down with the increasing board size. The third is that before 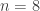
Removing the small board sizes yields:

Speed Ratios, Log Scale, Without Outliers
which shows that the respective implementations are well behaved (except for C# and its most probably JIT-related extra 7ms).
So we see that Bash is about 10,000 times slower than the optimized C++ version. The constant-propagated version is only a bit (~5%) faster than the generic C++ version. The Java version takes about 1.5× the time of the C++ version, which is way better than I expected—don’t forget that this is a native-code version of the Java program, it doesn’t run on the JVM. The C# version is twice as slow as the C++ version, which is somewhat disappointing but not terribly so. The Python versions are 120× (for the more pythonesque version) and 200× slower. That’s unacceptably slow, especially that the Python programs aren’t particularly fancy nor complex. We do see that using pythonesque idioms yields a nice performance improvement—40%—but that’s still nowhere useful.
*
* *
So what does this tell us? For one thing, that Bash is slow. But that Bash is slow even when it doesn’t use any external command should not come as a surprise. From what I understand from Bash, data structures are limited to strings and arrays. Lists and strings are the same. Basically, a list is merely a string with items separated by the IFS character(s), which causes all array-like accesses to lists to be performed in linear time as each time the string is reinterpreted given the current IFS. So even though a construct such as ${x[i]} looks like random-access, it is not. As for explicitly constructed arrays (as opposed to lists), there seems to be a real random-access capability, but it’s still very slow. I do not think that bash uses something like a virtual machine and an internal tokenizer to speed up script interpretation. Maybe that’d be something to put on the to-do list for Bash 5? In any case, I also learnt that Bash is a lot more generic than I thought.
The other thing is that Python is not a programming language for compute-bound problems. This makes me question how far projects such as Pygame (which aims at developing a cromulent gaming framework for Python) can go. While all of the graphics and sound processing can be off-loaded to third party libraries written in C or assembly language and interacting with the platform-specific drivers, the central problem of driving the game itself remains complete. How do you provide strong non-player characters/opponents when everything is 100× slower than the equivalent C or C++ program? What about strategy games? How can you build a MMORPG with a Python engine? Is a MMORPG I/O or compute bound? Could you write a championship-grade chess engine in Python?
My guess is that you just can’t.
And that’s quite sad because I like Python as a programming language. I used it in a number of (I/O-bound) mini-projects and I was each time delighted with the ease of coding compared to C or C++ (for those specific tasks). It pains me that Python is just too slow to be of any use whatsoever in scientific/high-performance computing. I wish for Python 4 to have a new virtual machine and interpreter to bring Python back with Java and C#, performance-wise. Better yet, why not have a true native compiler like gcj for Python?
*
* *
I am fully aware that the
*
* *
The raw data (do not forget that the two last timings for Bash are estimated). All times are in seconds.
| Language | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| C++ | 0.000000 | 0.000002 | 0.000003 | 0.000046 | 0.000005 | 0.000012 | 0.000036 | 0.000126 | 0.000569 | 0.002973 | 0.016647 | 0.080705 | 0.448602 | 2.830424 | 18.648028 |
| C++-fixed | 0.000000 | 0.000001 | 0.000001 | 0.000007 | 0.000005 | 0.000011 | 0.000033 | 0.000104 | 0.000500 | 0.002369 | 0.011468 | 0.065407 | 0.462506 | 2.765098 | 18.032639 |
| C# | 0.007315 | 0.007260 | 0.008356 | 0.007302 | 0.007864 | 0.007451 | 0.007421 | 0.008287 | 0.008452 | 0.012481 | 0.033548 | 0.154490 | 0.877194 | 5.444645 | 35.769138 |
| Java | 0.000001 | 0.000002 | 0.000002 | 0.000003 | 0.000005 | 0.000015 | 0.000049 | 0.000198 | 0.000895 | 0.004244 | 0.022947 | 0.128498 | 0.692349 | 4.457763 | 29.321677 |
| Python | 0.000012 | 0.000029 | 0.000054 | 0.000136 | 0.000424 | 0.001708 | 0.006078 | 0.026174 | 0.115218 | 0.546922 | 2.822554 | 15.405020 | 91.170068 | 581.983903 | 3762.739785 |
| Python-2 | 0.000012 | 0.000028 | 0.000045 | 0.000109 | 0.000318 | 0.001275 | 0.004125 | 0.017448 | 0.077854 | 0.348823 | 1.701767 | 9.349661 | 55.532111 | 339.244132 | 2259.010794 |
| Bash | 0.003054 | 0.010938 | 0.006067 | 0.011355 | 0.026913 | 0.091869 | 0.347451 | 1.472102 | 6.483076 | 30.813085 | 163.061341 | 891.828031 | 5031.663741 | 31746.000000 | 209162.000000 |
The More Pythonesque version:
#!/usr/bin/python -O
# -*- coding: utf-8 -*-
import sys
import time
########################################
##
## (c) 2009 Steven Pigeon (pythonesque version)
##
diag45=set()
diag135=set()
cols=set()
solutions=0
########################################
##
## Marks occupancy
##
def mark(k,j):
global cols, diag45, diag135
cols.add(j);
diag135.add(j+k)
diag45.add(32+j-k)
########################################
##
## unmarks occupancy
##
def unmark(k,j):
global cols, diag45, diag135
cols.remove(j);
diag135.remove(j+k)
diag45.remove(32+j-k)
########################################
##
## Tests if a square is menaced
##
def test(k,j):
global cols, diag45, diag135
return not((j in cols) or \
((j+k) in diag135) or \
((32+j-k) in diag45))
########################################
##
## Backtracking solver
##
def solve( niv, dx ):
global solutions, nodes
if niv > 0 :
for i in xrange(0,dx):
if test(niv,i) == True:
mark ( niv, i )
solve( niv-1, dx)
unmark ( niv, i )
else:
for i in xrange(0,dx):
if (test(0,i) == True):
solutions += 1
########################################
##
## usage message
##
def usage( progname ):
print "usage: ", progname, " <size>"
print "size must be 1..32"
########################################
##
## c/c++-style main function
##
def main():
if len(sys.argv) < 2:
usage(sys.argv[0])
else:
try:
size = int(sys.argv[1])
except:
usage(sys.argv[0])
return
if (size <= 32) & (size>0):
start = time.time()
solve(size-1,size)
elapsed = time.time()-start
print "%s %0.6f" % (solutions,elapsed)
else:
usage(sys.argv[0])
#
if __name__ == "__main__":
main()
The other versions can be found here in super_reines.zip. The Bash and C++ versions are somewhat Linux-specific.
1 A trick explained in detail in Brassard and Bratley, Introduction à l’algorithmique, Presses de l’Université de Montréal. Translated to English: Fundamentals of Algorithmics (at Amazon.com)
2 Frédéric Marceau translated the program from C++ to C#. François-Denis Gonthier translated from C++ to Java.
*
* *
So I added a third Python version to the archive. I also benchmarked it. It is quite a bit faster than the original one, and even than the ‘pythonesque’ version. For example:
$ super-reines.py 12 14200 15.966019 $ super-reines-2.py 12 14200 9.478235 $ super-reines-3.py 12 14200 6.845071
So a more ‘functional’ version performs about 2.3× faster than a direct translation from C++. For the same problem size, however, the C++ (fixed) version takes 0.069s… Roughly 100× faster than the 3rd version.

Speed Ratios, Log Scale, Without Outliers, with 3rd Python version

Hopefully by python 4 PyPy will be ready… however it’s a long time to wait (with unladen swallow happening inbetween).
The slowness of python is pretty frustrating, as the language feels ‘right’ in a number of ways, and going back to more verbose languages feels like a waste of typing.
I’m not a lawyer but I believe Microsoft’s EULA for the .net run time forbids publishing bench marked results and it’s one of the reasons I’ve seen a few people use the mono run time when benchmarking the language. Just a heads up.
Great article though, I’m really enjoying your series of articles using empirical methods to test assumptions about languages and structures, it reminds me to keep the science in computer science.
I didn’t know that. I used the mono run-time just because I am a linux-centric guy, having moved progressively away from windows in the last few years. So, basically just out of convenience, I used the compiler available from the ubuntu repository. Which also means that I measured gmcs’ performance rather than Microsoft’s compiler.
That’s not true as of 2005. The EULA does have specifics regarding benchmarking, though.
Not sure if I can link here, but this is the current wording: http://msdn.microsoft.com/en-us/library/ms973265.aspx
what happens if you type the program and compile it cython? that should speed it up to C++ execution speed, with a minimum of effort. experienced python programmers know that python is slow, but have understood that its not a big deal. there is an abundance of ways to speed up your python code.
try: “import psyco; psyco.full()”. likely you’ll get a 10* speed up or so. cython will speed up your code with slight more effort perhaps a hundred times.
I discussed the issue with friends about two months ago (at the time of writing) and someone suggested psyco (probably Gnuvince). For the readers that do not know, psyco is a just-in-time compiler addon for python, similar in spirit to the Java JIT. As I understand, psyco is unfortunately only available for 32 bits platforms and it turns out that most of my machines are in 64 bits mode.
Cython is not a python-to-C-compiler (I’d love that). From what I understand, it’s some kind of Python fork with tools to help you link C or C++ code with your now-not-quite-python application. Might as well just write everything in C or C++ then. I will still investigate this solution, however.
Neither cyton nor psyco have been integrated into debian / ubuntu repositories as far as I know. I know, that’s not a huge problem, but I’d rather have it in the package management system to get updates automagically. I had my share of installing stuff from tarballz, so I avoid it whenever I can.
True and False. Cython compiles code to the python C API, which isn’t the same at all as vanilla C/C++. Cython provides a very elegant path to high performance code.
What really bothers me in your post is the statement: “It pains me that Python is just too slow to be of any use whatsoever in scientific/high-performance computing”. Surely you haven’t even bothered to see scipy.org. With the tiniest bit of effort your post would have been more informative ( and correct for that matter ) and less pendantic at the same time ;’)
We must make the difference between using libraries written in other languages (again, you’re right, I haven’t fully investigated all possibilities) and native Python code written in Python only.
Maybe I wasn’t clear in my intention: I wanted to compare implementations using the given programming languages only. On that account, someone could (and probably will) complain that I didn’t use a similar mechanism for Bash, or even Java. I could have written parts of the C++ version in assembly language, why not? No, all the tests are self-contained, if you will; the language X implementation uses only language X code.
The bottom line remains, I think, that you can still write a wrapper for high-performance code in Python (as I state in the text as well) but that you can’t write the basic constituents of high performance code in Python: you can call an external library to invert a matrix but you probably don’t want to write that in Python.
What’s your take on this? How would you, for example, convert my Python code into “high performance” code? (this being said, I’m open to suggestions)
Well, I think typing a few variables or write assembler is a vast, vast difference. Python let’s you easily test various algorithms and approaches in little time, and provides simple and highly effective means of getting your code to the performance level of C. That is what is designed to do, pretty much in that order. You mentioned you’d like a gcj compiler for python. Which is called cython. Enough talk, I’m really curious to see what performance boost this will give you. Have you had a glimps at the performancepython link at scipy.org?
Yes, I’m browsing it as of now.
And if you want to try it for yourself, there’s a link with a zip containing all the source code.
I’ll have to read seriously about cython also.
ooops… forgot to post this link, which is very informative: http://www.scipy.org/PerformancePython
Another thing I haven’t done is checking the impact of compiler Python itself with different compilers. Someone told me that compiler Python with ICC (the Intel C Compiler) yielded *much* better results (lots of handwaving here) than compiling it with gcc. Anyone here tried this?
Have you heard of Shed Skin?
Shed Skin is an “Optimizing Python-to-C++ Compiler” that compiles ordinary Python code to C++ in order to speed up the code, typically by an order of magnitude or more over standard Python (and even over Psyco). Still in experimental form, but it works on a variety of real-world examples. (Full disclosure: I co-wrote the tutorial for it.)
http://code.google.com/p/shedskin/
You should consider using the self documenting feature for commenting your functions
http://python.about.com/od/gettingstarted/a/begdocstrings.htm
Yes, of course, you’re right. I usually do when I write large-ish code, but, well, obviously, I didn’t for this ‘toy program’
Social comments and analytics for this post…
This post was mentioned on Reddit by ptemple: Python in “dynamically typed interpreted language slower than statically typed compiled language” shocker. The conclusion appears to be: if RAD and maintainability is more important, you should use a lang…
Check out EVE online from CCP Games. It’s an MMORPG written in Stackless Python.
They say they have made the “game logic” in Python. This is nothing like making the full game in Python.
Why use GCJ and not the OpenJDK JVM?
> So I have decided to investigate by…
Google?
http://shootout.alioth.debian.org/u32/benchmark.php?test=all&lang=all&d=data&calc=calculate&gpp=on&java=on&csharp=on&python=on&python3=on&box=1
As long as you had fun ;-)
your main point is valid but there are some easy optimisation to make to your python code.
The global lookup is quite costly, so that would be the first suspect.
Also a bit of profiling would get you much better result. (solve could likely be written differently).
Two things to remember:
– first : you are not very experimented in python, hence a negative bias on the performance of the python prog. (ask on stack overflow, there are quite python expert there)
– second : more importantly, what are you measuring ? the speed of the language or the time needed to make a program with a minimum speed level. If you measure the first point, all is right, but I think the second is more important and valuable, and in this case, the test needs to be done differently.
“solve could likely be written differently” : pray tell how.
I just wanna say one thing: Fast/Slow is relative (for those that never noticed :)); Our brains can capture and interpret 25 frames per second. Do you really need to project movies at 500 fps? No. You wouldn’t be able to tell the difference anyways.
My point is: There are games out there done in Python. And it works. It’s fast enough. So unless you are talking about a very specific problem that really requires the fastest of languages, I don’t think anything is gained by stating that Python is slow.
Btw, EVE Online… Python (Stackless Python, but Python nonetheless) ;)
Peace
Fast/Slow doesn’t make a difference if you’re considering a game that is bound by the user. For example, at one extreme, solitaire and “five or more” are games that just wait for the player. I suppose simple shoot-them-up are in this category as well, where computation is still dominated by the rendering and video effects.
Fast/Slow makes a difference when you’re talking about a game that needs a lot of intelligence to be played right. Chess in an example of the other extreme. It’s not action-based, 70 fps rendering, but still a game. The only way of playing it correctly is to have a fast program. Smart, fast program.
I’m sure there are a number of hard-core gamers that could enumerate a long list of RPG-style games where the NPCs (non-player characters) would gain immensely from more complex (and therefore more costly?) programming. That would be a realistic case of the ‘in between’ case where you do not have to be blinding fast but fast enough to not let the user feel lag, and where you still need a lot of (non-rendering) computation.
Fast/Slow also makes a huge difference on the infra-structure. Maybe your program is I/O bound so it doesn’t really matter. What if it’s compute-bound or something in between? Something mostly I/O bound but that needs burst of computations to be performed? How many servers do you need to have a decent response time? Could you do with fewer servers if your program was much faster? I’ve discussed this in a previous entry a while ago: you’re in this situation where you have to balance ease of development/maintenance with infrastructure costs (computers, space, cooling, power, maintenance, etc). A data center gets expensive real fast.
(BTW, have you even seen a CRT screen flicker despite a 85Hz refresh rate? We do see a lot more than 25 fps… We just accomodate ourselves with slow frame rate. There’s a reason why most TV / movie standards have framerates above 24 fps.)
Fair enough. I was just illustrating the point that speed is always relative.
It’s like the old discussion that java is/was slower than a natively compiled language: It’s a useless argument unless you specify your problem at hand.
Well the world is bigger than computer games. From my experience Python is NOT a good idea for highly computational problems and mathematical modelling. I can understand someone arguing about using Java for such a complex task (rather than proven winners C and C++) but Python, that’s just unheard of… So yes, fast/slow kinda does matter just not in any domain!
I never use Python whenever I have moderately compute-intensive to do. Of course not! I tend to rely on SIMD-capable libraries, C++, and, yes, not too often, assembly language (as someone else suggested).
Most, if not all popular game engines use scripting languages, NOT C++ to abstract the game logic. Examples are Crysis (Lua), Unreal Engine (Unreal Script), Id tech engines (virtual machines), Eve online (Stackless Python) etc. The actual rendering stage is the real bottleneck here.
There are two implementations of the Python language running respectively on .NET and Java’s virtual machines:
1) http://www.codeplex.com/IronPython (up to 2.6)
2) http://www.jython.org/ (up to 2.5.1)
I’ve never tried them, really, so I have no idea about their performances.
By the way, Guido Van Rossum has declared a suspension from adding new features to the language for at least 2 years after that the 3.1 version of the Python main implementation will be released, just to allow such implementations (well, PyPy too), to catch up with new language features.
http://python.org/dev/peps/pep-3003/
I want to try IronPython but it turns out it’s Windows only. It’s not a big deal, but Windows isn’t part of my development environment anymore. I haven’t tried Jython either.
I think the most promising approach is like that of Shed Skin, linked to in a comment above. Analyse the python code and generate a fast, native code executable version of the program. I’m not that excited about byte-code and virtual machines and JIT (although it’s clear that if you go for virtual machines with byte-code, you MUST have JIT).
I read that IronPython can run also under Linux, with Mono:
http://www.ironpython.info/index.php/Mono
I tried it right now and it looks like it works, at least for an hello world. :-)
Of course, instead than the Microsoft Installer package I had to download IronPython-2.6-Bin.zip.
Most of EVE Online (a MMORPG) is written in Python.
PyPy does a pretty good job on this one:
alex@alex-laptop:~/Desktop$ python queens.py 12
14200 6.475548
alex@alex-laptop:~/Desktop$ ~/projects/pypy/pypy-c queens.py 12
14200 2.627967
What about, say, C++ on your box ?
[…] This post was mentioned on Twitter by Andreas Schreiber, all2one, vertoda, Tech news, ksaver and others. ksaver said: RT @programmingjoy: Is Python Slow? #programming http://bit.ly/4jyzWm […]
I tried compiling queens.py with Shed Skin. The only change I had to make to the code was to hard-code the size argument in main() rather than using sys.argv[]. It compiled right away, and here are the results with size=12:
Time required by standard Python version: 7.3 sec.
Time required by Shed Skin: 0.5 sec.
This order-of-magnitude speed-up was extremely easy to achieve!
That’s pretty darn impressive.
So what are, in a nutshell, the current limitations of Shed Skin ?
Let me add to my last reply before I respond to your question.
1.) In my last reply I used the “pythonesque” version of your code. But when I use the other (earlier, more C-like) version instead, the speed-up factor is even better. For size=12:
Time for standard Python version: 17.8 sec.
Time for Shed Skin: 0.12 sec.
2.) So, what are the restrictions ?
Basically, Shed Skin only handles a subset of Python that is less dynamic (and more like C++) than standard Python. Specifically, variables must have static typing (if you define a=1 you can’t subsequently define it as a=’hi’), and container variables should be homogeneous, i.e. a list such as [1,2,3] is allowed but not [1, 2.3, ‘4’]. Other common Python features are not supported, such as generators, multiple inheritance, and nested functions/classes.
Also, Shed Skin is experimental, so you may encounter bugs (which the creator, Mark Dufour, is happy to fix in my experience), and it hasn’t been tested on programs longer than one or two thousand lines.
Still, I have found it surprisingly easy to use, so I encourage you to experiment with it.
Why are all the y-axis labels to 6 places?
Those 6 decimal places are zeros in all the labels in all the charts.
Thanks, in the name of all readers, for that insightful comment, WHICH IS UTTERLY POINTLESS.
Oh, the irony.
From your comment I infer that you consider that pointless comments shouldn’t be made (conclusion A). OTOH, from the fact that you *do* comment, I infer (using conclusion A) that you consider criticizing pointless things “pertinent” (conclusion B).
Now, the comment that you label as “pointless” is itself criticizing a pointless thing (labels in a graph having unnecessary decimal places), so by your logic, it must be “pertient” (by conclusion B).
Either you fail at labeling Isaac’s comment as “pointless” (by conclusion B), or you fail at implying that Isaac shouldn’t have written it, since your comment would be equally pointless, and you *did* comment (if you negate conclusion B, conclusion A must be negated too).
Because the axes are really, really super precise.
(seriously, defaults settings in gnumeric with a log scale)
Reading on SciPy and NumPy, and other resources, I wrote yet another version, this time more functional in style:
def solve( niv, dx, cols, diag135, diag45 ): global solutions, nodes if niv > 0 : for i in xrange(0,dx): if not( (i in cols) or \ ((i+niv) in diag135) or \ ((32+i-niv) in diag45)): solve( niv-1, dx, [i]+cols, [i+niv]+diag135, [32+i-niv]+diag45 ) else: for i in xrange(0,dx): if not( (i in cols) or \ ((i+niv) in diag135) or \ ((32+i-niv) in diag45)): solutions += 1This version yields an interesting speed-up:
> super-reines.py 12
14200 15.966019
> super-reines-2.py 12
14200 9.478235
> super-reines-3.py 12
14200 6.845071
I think, Yes. From the above mentioned statistics, Python is slow as compared to Java. Java has acquired globally acceptance just because of it is platform independent.
[…] Is Python Slow? Python is a programming language that I learnt somewhat recently (something like 2, 3 years ago) and that I like very […] […]
[…] Pigeon fragt sich »Is Python Slow?« und liefert auch gleich ein paar Benchmarks mit (bitte auch die Kommentare beachten). [Harder, […]
I’ve found the source of the 7ms anomaly for Mono C#. At the first call of DateTime.Now the Mono class library initializes a handful of data that it needs to properly return the result for the current timezone.
There is a loop which calculates some data related to the start and end of daylight saving time during one year. Most of that processing is done in native code so it’s actually quite fast but does enough system call in a loop to cause a significant delay.
Once you add a dummy DateTime.Now call right before the first call to DateTime.Now, this calculation stays cached and valid and the delay is eliminated.
Another alternative would have been to use DateTime.Ticks to get the time at a 100ns resolution with little overhead. DateTime.Ticks is probably the thing to use for tight benchmarking.
I think this is a bug in Mono, and know a way to mitigate that effect, but the real problem is that DateTime.Now should return the system time right at the return of the Now property, but I don’t know how to solve the bug that way.
Indeed, changing the original code for so that DateTime is instanciated before it is used:
Does solves the problem.
@fdgonthier: System.Diagnostics.Stopwatch can be used for benchmarks, too.
Indeed, the code:
chrono.Reset(); chrono.Start(); solve(dx - 1, dx); chrono.Stop(); TimeSpan z = chrono.Elapsed;makes a lot more sense.
@fdgonthier: Still something you should file as a bug to the mono developpers. 7ms is a lot of drift between “now” and the time the function actually finishes.
Fixing the C# version with either the dummy variable or the
Stopwatch(while the latter makes more sense) gets rid of the 7ms. There’s still a little something, but now it’s about 200µs, so it’s not really a major issue. Still strange, though.멤피스의 생각…
Is Python Slow? « Harder, Better, Faster, Stronger…
[…] Programming, boost, template | A few weeks ago, a friend posted an article on his blog about python being slow by comparing implementations of the 8 queens puzzle in different languages using a recursive […]
Thanks for this great article
EVE online not that fast, as seen on a /. story.
I ran a very similar experiment though you went through greater lengths with analysis and had pretty much the same results. Python was slow, but did you try running your Python code on the JVM with Jython? It was so slow that it made Python look fast.
No, I didn’t try Jython, although one of my friends did, and the results were far from encouraging. He ran a somewhat similar test, one that’s essentially recursive, the construction of a tree and python, even on jython, was really much slower than other (similar-ish) languages such as native Java, Haskell (if I remember correctly) and some other language like ocaml.
There’ll be a follow up on this post sometime soon, I will include Jython and others that I can (not all are available for 64 bits platform yet, or if they are, haven’t made their way into the Ubuntu repositories, which is a major bummer.)
I went to our Cambridge, MA Python Meetup speaker preview before PyCon (two in the last 3 weeks) and there is a lot of discussion about speed with Python and improvements coming up.
A short talk that explains some of the issues with Python:
Unladen Swallow: fewer coconuts, faster Python
[…] Python Slow? (Part II) In a previous post I expressed my worries about Python being excruciatingly slow and I used a toy problem to compare […]
[…] have increased steadily over the last year, principally due to a few shocking posts such as Is Python Slow? and high-visibility posts such as the CFM-00 (which was featured on Hack-a-Day). The first post […]
There are so many other programming languages that are arguably “nicer” than python, i.e. more elegant, more concise, better support for high level abstracgtions .. .whatever .. AND they are faster than Python Why try so hard to cling to python? All the python libraries are written in C, C++ aren’t they? It should be just as easy to interface with existing python libraries in a modern fast programming language as in Python. Look at Clojure. It leverages all the existing java libraries.
Python — just say no.
[…] than C++, and that’s some what new for me. Of course, I’ve criticized Python’s dismal performance on two occasions, getting me all kind of comments (from “you can’t compare […]
[…] the n-queens problem I used before, I get the following […]
I did some informal benchmarks on n=13 on the python version, c++ version, and java versions. The python version is the one you printed here, I also ran the 2to3 converter on it. Data:
Python2.6: 31.450s
Python3.1: 24.196s
Jython2.5: 26.871s
PyPy1.6: 06.547s
Java on Sun JVM with naked javac: 0.422s
C++ (fixed), naked g++: 0.695s
C++ fixed, your options: 0.231s
C++ just -Os: 0.283s
C++ your ops with -pipe -march=native: 0.227s
This doesn’t bother me that much, and PyPy continues to get faster with every release, it’s really not that slow anymore. PyPy continues to impress: http://speed.pypy.org/ Parallelism is where it’s at anyway. (Ignore the GIL behind the curtain.) I don’t really agree with the conclusions of this old post.
Python 3 is easier, better and faster. So I think you should have done a benchmark of that.
Probably. At the time I did this, I’m not sure it was out. Anyway, the latest production version is 2.7.x. I’m not sure python 3 is universally available on all distros (there are advantages to stick to distro-approved versions).
[…] right-hand sides will depend on previously (or concurrently) computed left-hand sides. Remember, in Is Python Slow? I used the generalized 8 Queens problem to test the efficiency of different programming languages. […]
after python what new next language ? too many language make me be an idiot,
Some people think there are too many languages, and I think I would agree with them except for the fact that different languages try to solve different problems or use different approaches to the same problems. Python, for example, is a really fun language to use: not too complicated, you can write some things really fast, and it is flexible enough that you never really end up in a dead end. However, Python is a language that is meant to be fun, simple, and flexible. By design it doesn’t care if it’s efficient or not (and even at times it seems it makes an effort not to). C is at the other extreme: by design it’s meant to be efficient, to let you control very finely what will happen in the machine, and guess what will be the (most likely) generated code, but does nothing to help you; you have to do everything by yourself. Take for example string manipulation in C. About as fun as putting your contact glasses with a fork.
In either case, it’s not a limitation if it’s by design.
This being said, I try to limit the number of different languages I use, otherwise I feel I never use one language fully, just write something in that language that I could have written in any other language. That is, it is hard to stop writing C++-style code in Python, but once you’ve grokked the spirit of the language (whether python or Java or some other), it’s usually much more pleasant.
“Cython compiles to C or C++ code rather than Python” (from http://en.wikipedia.org/wiki/Cython).
“The source code gets translated into optimized C/C++ code” (from http://docs.cython.org/src/quickstart/overview.html).
This is a nice discussion about Cython performance: http://news.ycombinator.com/item?id=1845696
http://radiofreepython.com/episodes/8/ has an excellent interview with Kristjan Valur Jonsson. Kristjan covers a lot in his talk, including Eve Online, stackless, greenlets and CCP Game’s rationale for Python: programmer productivity. (He comments that programmer productivity is “money in the bank”.) So what do you want to optimize: execution speed, memory, or programmer productivity? It’s a fascinating talk.
You formulate your question as a XOR question. It’s about AND. You want to optimize programmer productivity, but not at the cost of having a slow, bloated, needs-a-data-center, product. You want to optimize both.
Right. My comments may be seen as suggesting mutually exclusive solutions, but that’s not the intent, which is to be informative and stimulate deeper investigation by readers.
It’s difficult, impossible, actually, to optimize everything, but Python offers solutions that can help optimize the most important things.
Evidently Cython allows easy switching between productivity and performance optimization in a way that supports both.
I cited the Kristjan Valur Jonsson talk because he gives a nice discussion of (his) optimization choices for a complex system. (There’s no point in using Stackless Python unless you need the concurrency, and even then, there are other options with their own tradeoffs.)
Q: Is Python slow? A: Not if it meets your performance requirements for the job at hand. If it’s still too slow, it need not be: use Cython (with annotated types); profile your code and then speed up the slow parts; use a more efficient algorithm; call C code.
Then we mostly agree, I suppose. My point was not that Python wasn’t fast enough for task X, but that its very core, it’s a slow interpreter, a bit of a quantitative caveat emptor on performance.
(and I still haven’t listened to the podcast, but it’s on my queue)
Exactly.
Every language that has shown itself to be suitable for compute-intensive applications has the property that the runtime for the language is largely written in the language itself. The “I’ll just escape to C” approach systematically defers issues of how the language design interacts with the potential for a high performance runtime system until it is too late.
if speed is your sole concern, learn and use assembly
Wow, that’s a shallow reply. What the hell makes you feel like the author of this article is solely interested in speed? Computer Science is all about trade offs and a factor 100 against a little more typing effort can make a huge difference (not talking about games here).
It amazes me how many Python apologists have commented all to say something between “It doesn’t matter if it’s slow” and “it’s not slow”.
If that’s the case, why aren’t you all using your 16MHz processors?
I ended up here because a tight loop in Python which does nothing but pump integers onto a queue is running ~100 time slower than the C# client which listens to the queue _and processes the results_.
Speed _does_ matter. I like Python. It’s got a lot of positives about it but it is not fit for number-crunching, no matter how you try and justify it.
Exactly. Sometimes speed does not matter; sometimes it does. When you consider scaling, that is, having tens or hundreds of thousands clients at the same time, somehow, something slow does not work, sometimes to a point where even adding computers and CPUs and all the infrastructure still does not cut it. But, hey, my homework finished in a few seconds, surely it’s fast enough :p
Ah, …bait: “Python apologists” and “using your 16MHz processors” and “not fit for number-crunching”. Yeah, unfit at any speed and Pythonazis, too! (Hey, I just made that up. :-)
Yes, “Speed _does_ matter”, but your performance_requirements matter equally:
— Does an implementation in Python meet your performance_requirements? If so, then Python is fast.
— If an implementation with a bad algorithm does not meet your performance_requirements, then you are slow.
— If an implementation with a good algorithm does not meet your performance_requirements, then Python is slow.
— If productivity is important to you and an implementation in Python meets your performance_requirements, then Python is _very_ fast.
…
— If productivity is important to you and an implementation with a good algorithm, careful optimization and other speed-up techniques does not meet your performance_requirements, then Python is _very_ slow.
— If productivity is not important to you, then you are slow, on island time, or…
“You”? No, not you-you, but someone else.
Since this discussion began, many things have changed.
(Of course, things always change, but at different rates…)
I found the following post to be very interesting and relevant:
http://jakevdp.github.io/blog/2013/06/15/numba-vs-cython-take-2/
Is the difference between Cython and Numba the result of different compilers?
Or you could switch to a very fast, efficient, small, easy to learn, typed, safe language, LIKE Oberon-2, Modula-3, Component Pascal–all basically the same language —and quit screwing around with WHAT-IFS.
I haven’t used any of those. In the olden times, I programmed a lot in (Turbo) Pascal. What do you think about Lua (which is also rather Pascalèsque)?
I’ve implemented the algorithm in Julia (reads almost like Python code), the test ran at juliabox.org using v0.5+, it’s fast! <3
source: http://git.io/v0O7z (see comment there)
n t (seconds)
7 0.000028
8 0.000108
9 0.000463
10 0.002146
11 0.010646
12 0.057603
13 0.334600
14 2.055078
15 13.480449
16 97.192552
17 720.314676
Here is an IJulia notebook with the code in Julia: bit.ly/NQueens_ipynb
Cool!
Weird how time jumps between n=8 and n=9. Any idea why it’s so?
I believe you could now use Numba to speed up this program’s execution as well, I’d be curious to give it a try.